LakeSoul Flink CDC Whole Database Synchronization Tutorial
LakeSoul Flink CDC Sink supports the entire database synchronization from MySQL to LakeSoul, and can support automatic table creation, automatic schema change, exactly once semantics, etc.
For detailed documentation, please refer to LakeSoul Flink CDC Synchronization of Entire MySQL Database
In this tutorial, we fully demonstrate synchronizing a MySQL database to LakeSoul, including automatic table creation, DDL changes and other operations.
1. Prepare the environment
1.1 Start a local MySQL database
It is recommended to use the MySQL Docker image to quickly start a MySQL database instance:
docker run --name lakesoul-test-mysql -e MYSQL_ROOT_PASSWORD=root -e MYSQL_DATABASE=test_cdc -p 3306:3306 -d mysql:8
1.2 Configuring LakeSoul Meta DB and Spark Environment
For this part, please refer to Setup a local test environment
Then start a spark-sql SQL interactive query command line environment:
$SPARK_HOME/bin/spark-sql --conf spark.sql.extensions=com.dmetasoul.lakesoul.sql.LakeSoulSparkSessionExtension --conf spark.sql.catalog.lakesoul=org.apache.spark.sql.lakesoul.catalog.LakeSoulCatalog --conf spark.sql.defaultCatalog=lakesoul --conf spark.sql.warehouse.dir=/tmp/lakesoul --conf spark.dmetasoul.lakesoul.snapshot.cache.expire.seconds=10
This command starts a Spark local job, adding two options:
- spark.sql.warehouse.dir=/tmp/lakesoul This parameter is set because the default table storage location in Spark SQL needs to be set to the same directory as the Flink job output directory.
- spark.dmetasoul.lakesoul.snapshot.cache.expire.seconds=10 This parameter is set because LakeSoul caches metadata information in Spark, setting a smaller cache expiration time to facilitate querying the latest data.
After starting the Spark SQL command line, you can execute:
SHOW DATABASES;
SHOW TABLES IN default;
![]()
You can see that there is currently only one default database in LakeSoul, and there are no tables in it.
1.3 Create a table in MySQL in advance and write data
- Install mycli
pip install mycli - Start mycli and connect to the MySQL database
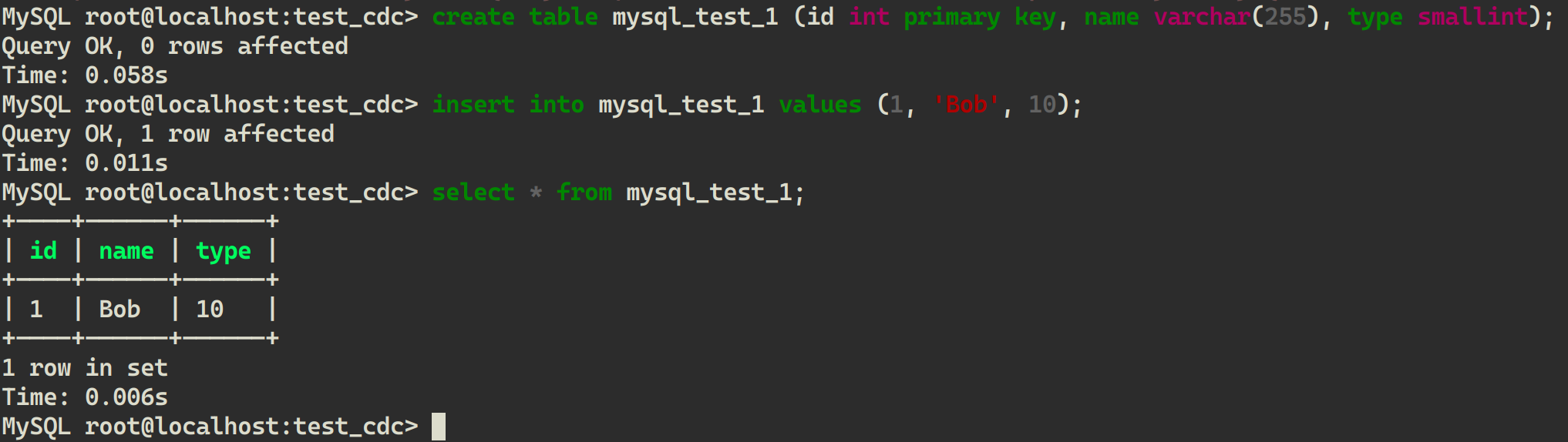
mycli mysql://root@localhost:3306/test_cdc -p root - Create table and write data
CREATE TABLE mysql_test_1 (id INT PRIMARY KEY, name VARCHAR(255), type SMALLINT);
INSERT INTO mysql_test_1 VALUES (1, 'Bob', 10);
SELECT * FROM mysql_test_1;
2. Start the sync job
2.1 Start a local Flink Cluster
You can download from the Flink download page: Flink 1.20
Unzip the downloaded Flink installation package:
tar xf flink-1.20.1-bin-scala_2.12.tgz
export FLINK_HOME=${PWD}/flink-1.20.1
Then start a local Flink Cluster:
$FLINK_HOME/bin/start-cluster.sh
You can open http://localhost:8081 to see if the Flink local cluster has started normally:
![]()
2.2 Submit LakeSoul Flink CDC Sink job
Submit a LakeSoul Flink CDC Sink job to the Flink cluster started above:
./bin/flink run -ys 1 -yjm 1G -ytm 2G \
-c org.apache.flink.lakesoul.entry.MysqlCdc\
lakesoul-flink-1.20-3.0.0.jar \
--source_db.host localhost \
--source_db.port 3306 \
--source_db.db_name test_cdc \
--source_db.user root \
--source_db.password root \
--source.parallelism 1 \
--sink.parallelism 1 \
--warehouse_path file:/tmp/lakesoul \
--flink.checkpoint file:/tmp/flink/chk \
--flink.savepoint file:/tmp/flink/svp \
--job.checkpoint_interval 10000 \
--server_time_zone UTC
The jar package of lakesoul-flink can be downloaded from the Github Release page.
Refer to LakeSoul Flink CDC Synchronization of Entire MySQL Database for detailed usage of the Flink job.
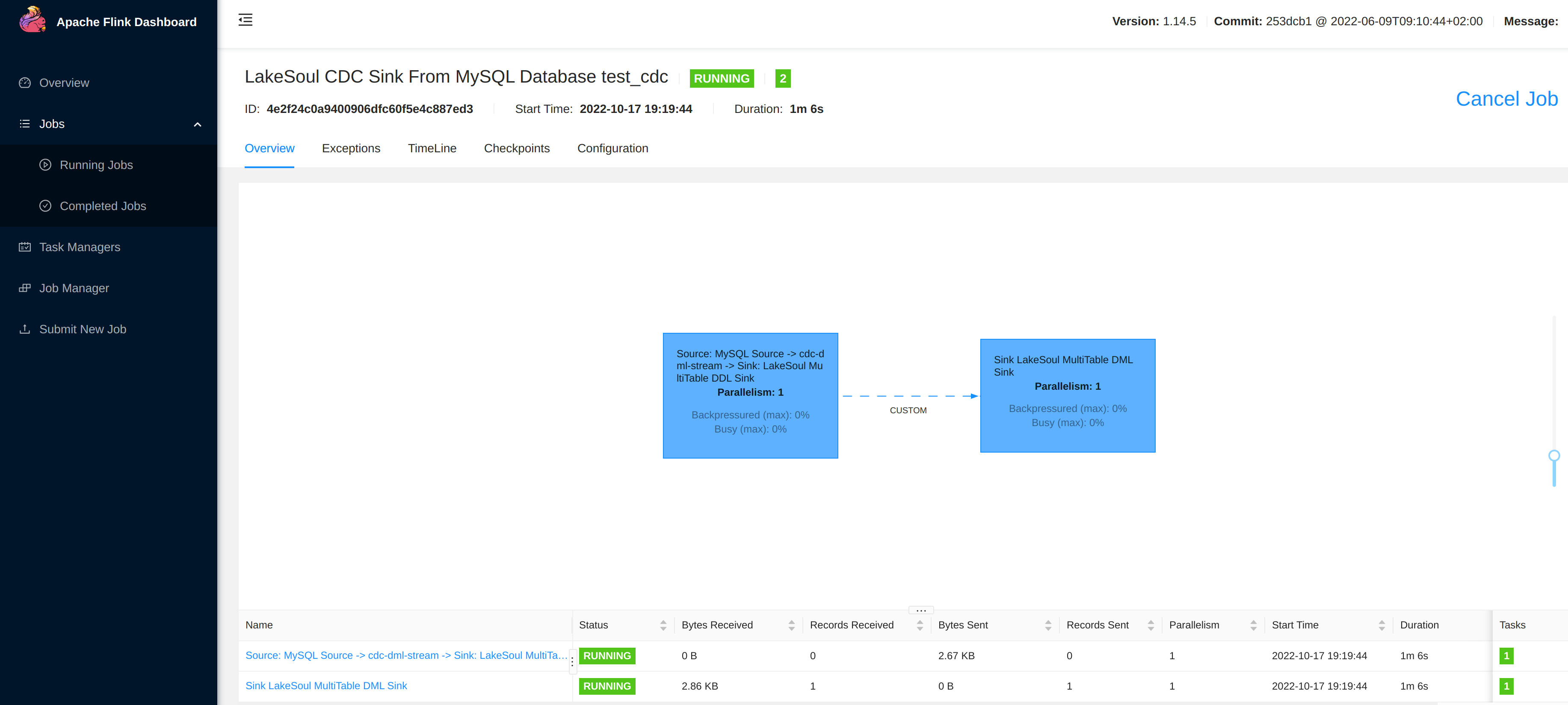
On the http://localhost:8081 Flink job page, click Running Job to check whether the LakeSoul job is already in the Running state.

You can click to enter the job page, and you should see that one data record has been synchronized:
2.3 Use Spark SQL to read the synchronized data in the LakeSoul table
Execute in Spark SQL Shell:
SHOW DATABASES;
SHOW TABLES IN test_cdc;
DESC test_cdc.mysql_test_1;
SELECT * FROM test_cdc.mysql_test_1;
You can see the running result of each statement, that is, a test_cdc database is automatically created in LakeSoul, and a mysql_test_1 table is automatically created. The fields and primary keys of the table are the same as those of MySQL (one more rowKinds column, refer to the description in LakeSoul CDC Table).

2.4 Observe the synchronization situation after executing Update in MySQL
Perform the update in mycli:
UPDATE mysql_test_1 SET name='Peter' WHERE id=1;
Then read again in LakeSoul:
SELECT * FROM test_cdc.mysql_test_1;
You can see that the latest data has been read:

2.5 Observe the synchronization after executing DDL in MySQL, and read new and old data
Modify the structure of the table in mycli:
ALTER TABLE mysql_test_1 ADD COLUMN new_col FLOAT;
That is to add a new column at the end, the default is null. Verify the execution result in mycli:

At this point, the table structure has been synchronized in LakeSoul, and we can view the table structure in spark-sql:
DESC test_cdc.mysql_test_1;

At this time, read data from LakeSoul, and the new column is also null:
SELECT * FROM test_cdc.mysql_test_1;

Insert a new piece of data into MySQL:
INSERT INTO mysql_test_1 VALUES (2, 'Alice', 20, 9.9);

Read again from LakeSoul:

Delete a piece of data from MySQL:
delete from mysql_test_1 where id=1;
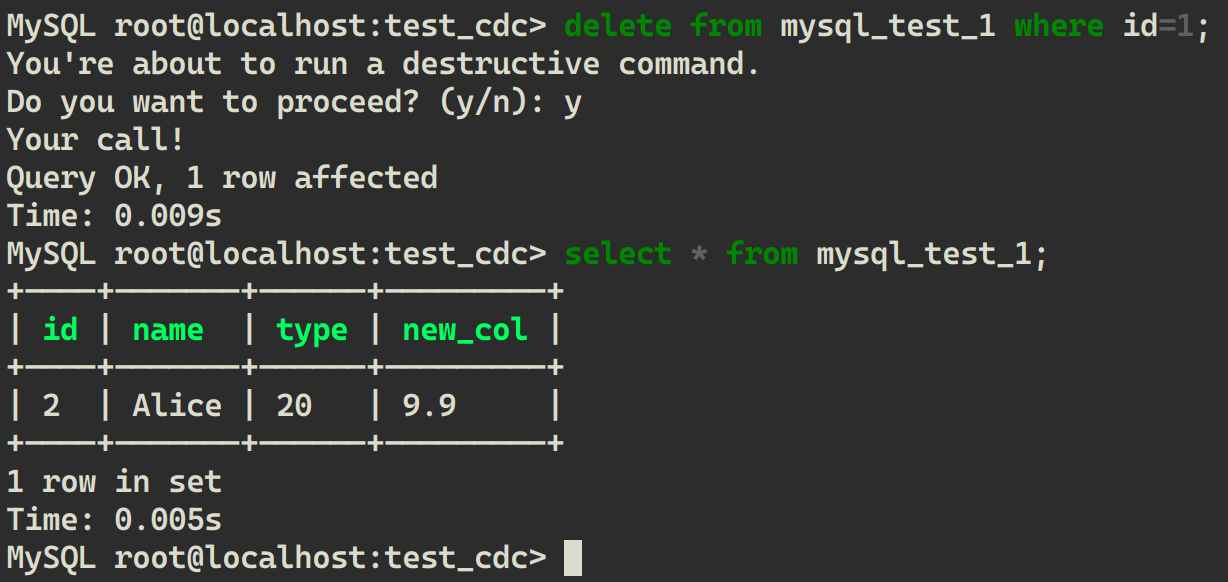
Read from LakeSoul:

**You can see that LakeSoul reads the synchronized result every time, which is exactly the same as in MySQL. **
2.6 Observe the synchronization after creating a new table in MySQL
Create a new table in MySQL with a different schema from the previous table:
CREATE TABLE mysql_test_2 (name VARCHAR(100) PRIMARY KEY, phone_no VARCHAR(20));
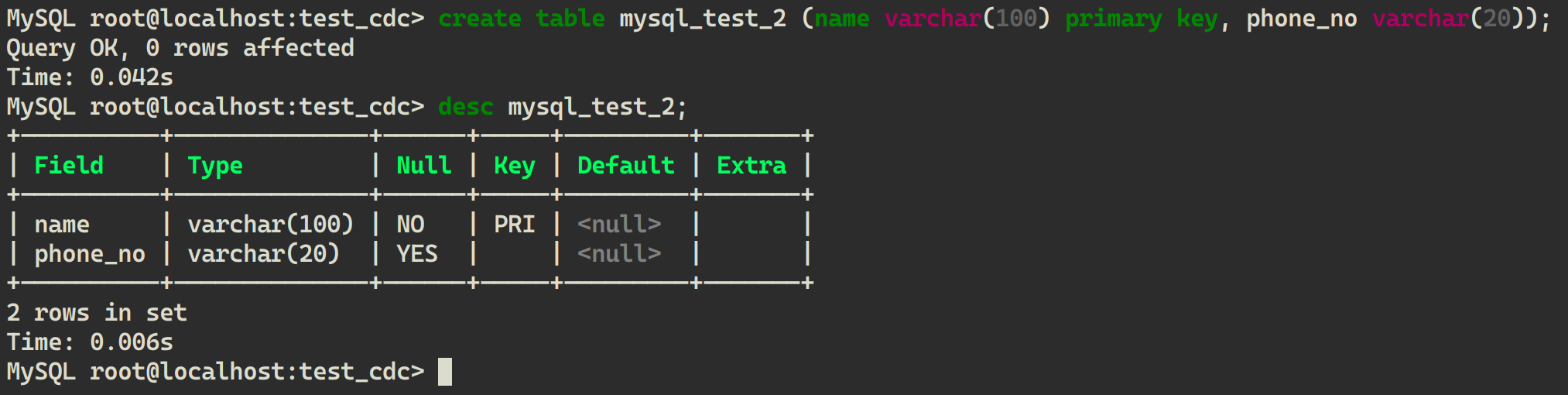
In LakeSoul, you can see that the new table has been automatically created, and you can view the table structure:
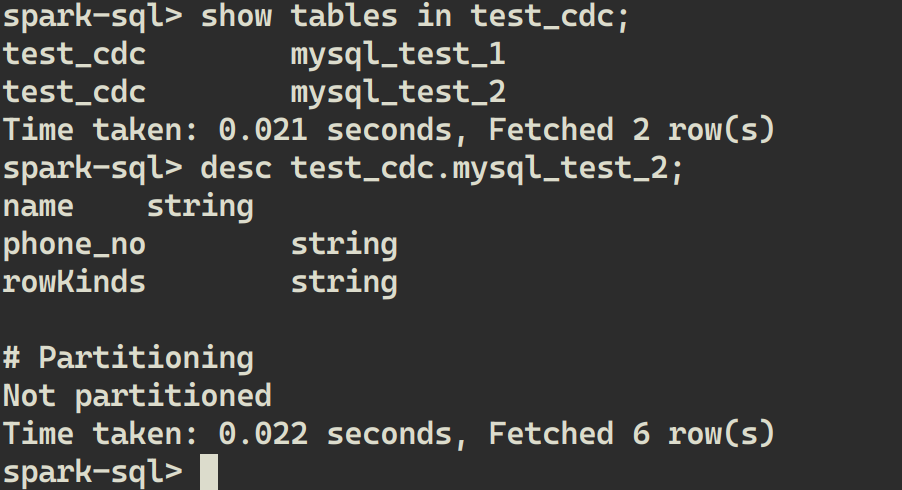
Insert a piece of data into a new MySQL table:
INSERT INTO mysql_test_2 VALUES ('Bob', '10010');
LakeSoul also successfully synchronized and read the data of the new table:
