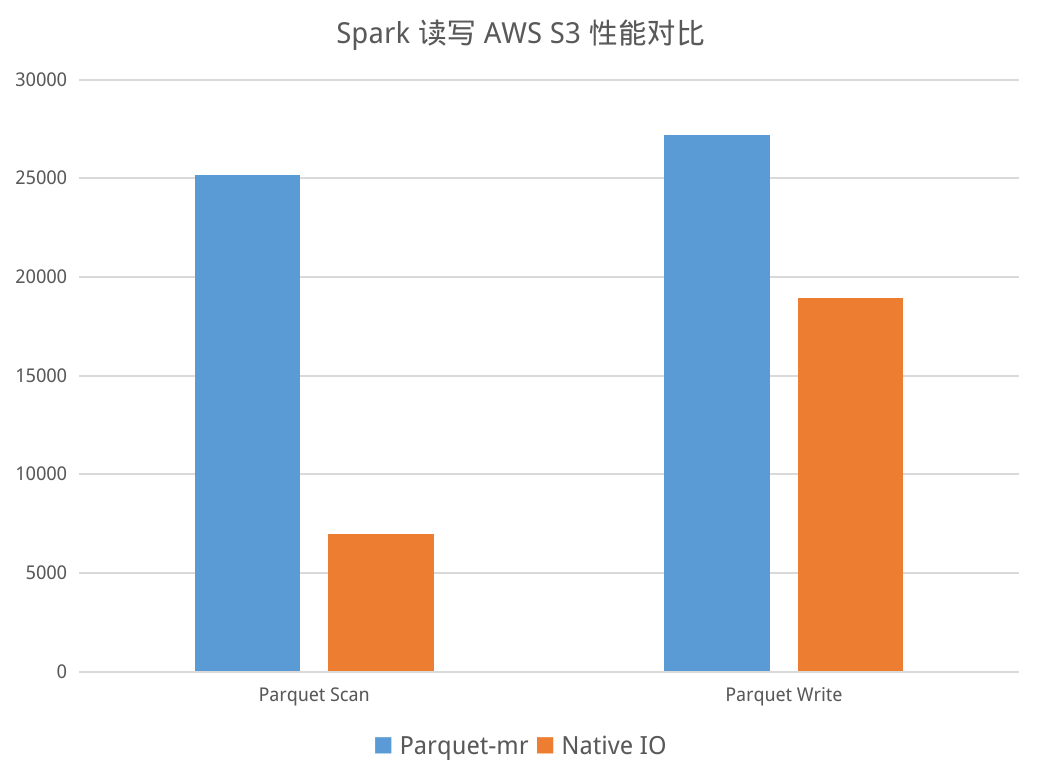
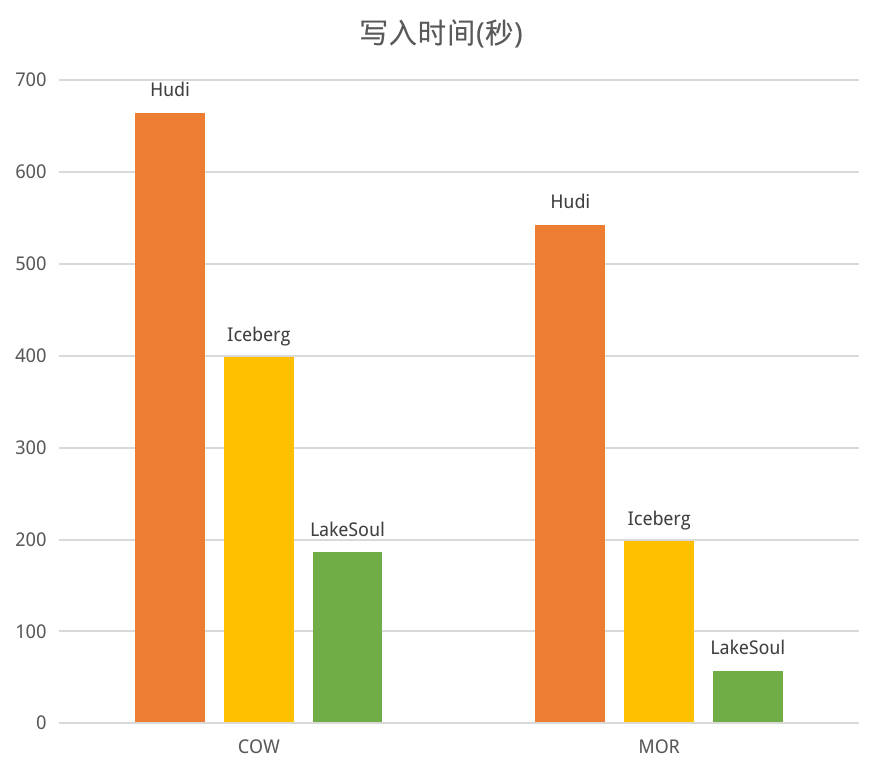
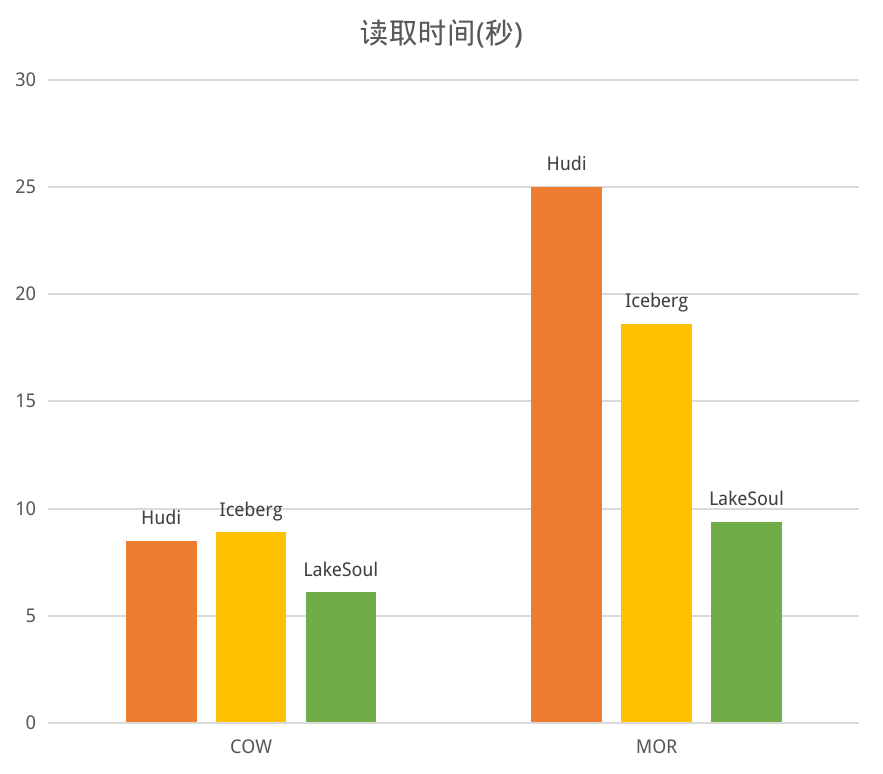
近期,湖仓框架 LakeSoul 发布了 2.3.0 版本。本次新版本发布是 LakeSoul 进入 Linux 基金会孵化后的第一次版本发布。本次新版本新增 Flink SQL/Table API,支持流、批的读写。重构了多表实时入湖的 Flink DataStream API,以更好地支持多种数据源的实时入湖。新增了全局自动小文件合并服务。
Flink SQL/Table API
LakeSoul 在 2.3.0 版本中,全面支持了 Flink SQL/Table API,同时支持流、批两种方式,对 LakeSoul 表进行读或写。在流式的读取或写入时,LakeSoul 完整地支持了 Flink Changelog Stream 语义。
在流式写入时,可以对接多种 CDC 采集工具,包括 Debezium、 Flink CDC Connector,支持行级别 upsert、delete;在读取时,对于 Append 或 Upsert 方式增量更新的表,均可流式增量读取,并在 Flink 中进行增量计算。同时,LakeSoul 也支持 Flink 批计算模式,能够支持批量 upsert、全量读取、快照读取等功能。
使用 LakeSoul + Flink SQL,可以很方便地在数据湖上构建大规模、低成本、高性能的实时数仓。具体使用方法可以参考 Flink SQL 文档。
Flink 多源入湖 Stream API
LakeSoul 从 2.1 版本起能够支持数据库整库同步,并提供了 MySQL 整库自动同步工具。
在本次 2.3 版本更新中,我们重构了整库同步时的 DDL 解析方式。具体来说,LakeSoul 在进行整库同步时不再需要上游提供 DDL 事件,或去上游数据库获取表的 Schema 等信息,而是直接从同步的数据中解析是否出现新表、是否已有表的 Schema 发生了变更。遇到新表或 Schema 变更时,会自动在 LakeSoul 湖仓中执行建表或 Schema 变更。
这个改动使得 LakeSoul 可以支持任意类型的数据源入湖,例如 MySQL、Oracle 的 CDC 采集,或者从 Kafka 中消费 CDC 事件。开发者只需要将 CDC 消息解析为 BinarySourceRecord 对象,并创建 DataStream<BinarySourceRecord>,即可实现整库同步。LakeSoul 已经实现了从 Debezium DML 消息格式到 BinarySourceRecord 对象的转换,其他 CDC 格式可以参考实现。
全局自动小文件合并(Compaction)服务
LakeSoul 支持流式、并发的 Upsert 或 Append 操作,每次 Upsert/Append 都会写入一批文件,在读取时自动进行合并(Merge on Read)。
LakeSoul 的 MOR 性能已经相对高效(参考之前的性能对比),实测在 Upsert 100 次后的 MOR 性能下降幅度约 15%。不过为了能够有更高的读性能,LakeSoul 也提供了小文件合并(Compaction)的功能。Compaction 功能是一个 Spark 的 API,需要对每个表独立调用,使用起来较为繁琐。
本次 2.3 版本更新,LakeSoul 提供了全局自动小文件合并服务。这个服务实际是一个 Spark 作业,通过监听 LakeSoul PG 元数据库的写入事件,自动触发对符合条件的表的合并操作。这个合并服务有如下几个优点:
- 全局合并。合并服务只需要在集群中启动一次,就会自动对所有表进行合并(也支持按 database 划分为多个),不需要再在各个表的写入作业中进行配置,使用方便。
- 分离式的合并服务。由于 LakeSoul 能够支持并发写,因此合并服务的写入不影响其他写入作业,可以并发执行。
- 弹性伸缩。全局合并服务使用 Spark 实现,可以通过开启 Spark 的 Dynamic Allocation 实现自动弹性伸缩。
LakeSoul 2.3 版本更新,能够更好地支持构建大规模实时湖仓,提供了高性能 IO、全链路流式计算、方便快捷的多源入湖等核心功能,全局合并服务在提升性能的同时保持了简单易用的特性,降低了数据湖的维护成本。
在下个版本,LakeSoul 还将原生支持 RBAC 权限控制、原生 Python 读取等功能。LakeSoul 目前是 Linux Foundation AI&Data 的 Sandbox 孵化项目,也欢迎广大开发者和用户参与到社区中来,一起打造更快、更好用的湖仓一体框架。